|
G. M. Kert, V.T.
Vdovitsyn and A.L. Veretin
Toponymic Research System of Northwest Russia: The TORIS System
Abstract
This paper describes results of usage of Saam toponyms database system of Kola peninsula to analyse
grammatical and semantic toponym features. Also we describe here implementations of methods of multy-agent theory to design a
prototype of distributed research database system to store and treat toponymic data basing on Internet / Intranet technology.
Key words: Toponym, database system, intelligent agent.
Introduction
The long-interest attracted by toponyms can be explained not only by their unusual functions, mysterious origin of most of them, distinctions of their grammatical features from the other word class, i.e. appellatives, but, also by the fact that they are rich in information needed to solve ethnogenetic problems.
The role of toponyms as accurate landmarks grows considerably in the process of the establishment of information-oriented society. An important task is then the development of a unified toponymic service as well as thoroughly checked regional toponymic databanks.
There are several historically established toponymic language zones in the European North of Russia: Russian, Karelian, Vepsian, Finnish, Saam, Komi, Nenets Mutual contacts and migrations of the population resulted in the appearance of the zones with interacting toponymic systems. In these bilingual and multilingual conditions canonical lists of place-names in different languages and a system of transliterating place-names from one language to another are to be created. Place-names as well as other manifestations of the people's spiritual culture, i.e. folklore, rites, believes etc. reflect peculiar national features and mentality. This makes protection of cultural heritage extremely important. This is especially so for the small nations of the North: Saams, Vepsians, Karelians, Nenets who are not able to withstand the pressure of modern culture independently. Not least important is a purely scientific study of toponymy (nomination principles, place-name adaptations in a foreign environment, ratio of appelative and toponymic vocabulary, etc.). All these tasks can be solved only by large research bodies working towards the specific aim with a unified technique. Thus it has become necessary to coordinate these broad and important activities.
Saam toponyms database system of Kola peninsula
In 1990 Institute of LLH KRC RAS got a good chance to make practical use of computers for the study of place-names. A student of the Department of Mathematics at Petrozavodsk University O.Kuzmina was offered the topic "Formalization of place-names (on the basis of the dictionary of Saam-names in the Kola peninsula)" for her diploma project. Later the work on entering place-names in the computer and selections from various records were continued by A. Lapin.
Saam place-names collected by the Finnish scientist K. Nickul in the 1930's near Petsalmo, Kola peninsula were used as the material for computerising toponymy. The reasons for choosing this very area were the following. The area covers a little over 100 km from West to East and more than 240 km from North to South and in the territory with undispersed population. Saam in this area are the least affected by the economic and language impact of both Russians and Finns. In fact the materials collected are a model of purely Saam toponymy not affected by foreign impacts.
As a result of preliminary investigations into the place-names of the region a database with the following structure was entered into the computer:
place-name identificator
the language of representation
place-name
the language of origin
one-component place-name
number of components
prefix
suffix
diminutive
determinant
definition in the nominative
definition in the genitive
definition in the oblique case
definition - verbal name
adjectival construction
analytical construction
semantic formula
the object's conformity to the name
appellative
map element
data collection site (source)
object
The database "Saam place-names" was developed with the PC Amstrad PS 1640.
1535 place-names were entered into the computer. Of the total number of place-names 1087 consist of two components, 376 - of three, 43 - of one, 28 - of four and one - of five components.
The structure of the data base allowed to carry out various selections concerning grammatical and semantic aspects of the place-name from the computer. E.g. 126 two-component place-names with the determinant jaur "lake" were selected from the whole bulk of words. In fact the determinant part of the place-name explained to a great extent the motivation of the name. One can only wonder how rich and imaginative the thinking of Saams who had given names to the lakes was. Let us name at least some of them in the alphabetic order: algash "sonny", gorshek "pot", karns "raven", koshk "dry", labdsh "belt", paht "mountain", paij "superior", pieds "pine", raut "iron", suelo "island", tshuenj "goose", vatts "mitten", vuash "horsetail", etc. We can add that the diminutive of the word jaur - jaurach is the determinant in 143 instances; repetitions of the definition of the determinant are quite rare. Here are some examples of the high frequency of determinant's use: vaar "mountain" - 128, luht "bay" - 77, njarg "cape" - 66, luobbal "running-water lake" - 67, jokk "river" - 55, suelo "island" - 47, etc.
According to the Onomastic Glossary by R.Hallig and Walter von Wartburg used to classify the toponymic vocabulary the greatest subsections in relation to the frequency of the vocabulary were: la Universe - a211 Waters, seas, rivers, a211 Landscape and minerals, a311 Plant life, a412 Field and forest animals, llb Man b151 Movements and actions, b353 Hunting, fishing, b381 Road, transport, b421 Ethnonyms, antroponyms, lllc Man and Universe - c211 Space and spacial relations.
The computer yielded a dictionary of toponymic vocabulary including substrate vocabulary, and the frequency of usage was determined for all lexemes. All in all 846 words were used to form 1535 place-names. The most frequently used groups of words were: water bodies - jaur "lake" - 188, jaura "lakelet" - 110, jaurash "lakelet" - 173, jokk "river - 88, luht "bay" - 106, oaij "stream" - 25; landscape objects - kiedge "stone - 15, njarg "cape" - 93, suelo "island" - 66; flora and fauna - njuhtsh "swan" - 10, njukkesh "pike" - 8; human activity objects - kuatt "vezha, Saam house" - 10, portt "log cabin" - 14, sijd "settement" - 11 etc.
Computerization of Saam toponymy was carried out as an experiment aimed at reveling the possibilities of using computers in the research. The results proved work with the computer to be rather useful. It has to be stressed though that the possibilities of the created data base are far from being used up. Later selections can be made for syntactic constructions, for determining the vocabulary of definitions and determinants, etc.
Toponymic research information system TORIS
The aim of the investigation is to design toponym oriented research information system TORIS to store and treat toponymic data basing on Internet/Intranet technology.
Currently in Russia accumulated huge toponymic data represent greater value for specialists when deciding concrete tasks in information, culture, history, and linguistic fields. Existing approaches to formalization and computerization of toponymic data are charectirized by local nature and in insufficient degree take information account into structure and semantic of toponyms. These and other defects cause need of investigation and development of more powerful and suitable for specialists tools for computerization of toponymic data to achieve holistic representation about information, culture, history, and linguistic toponym contents.
The TORIS server architecture consists of three basic elements (Fig. 1):
dbTORIS is a relational database to support SQL queries;
3wTORIS is a WWW application to input/output basic information;
agTORIS is a set of intellegent agents to perform various service tasks (assistance to filling SQL queries
forms, autonomous net search across the TORIS servers).
As a client-server architecture model we chose AS-model (Application Server) that consists of three layers:
presentation application to perform input/output information tasks, to be responsible for an interaction
between the 3wTORIS and user browser;
business application to join toponymic domain knowledge, to be responsible for an interaction between the
3wTORIS and agTORIS components;
resource manager to perform storage and data control function, in TORIS architecture it is the dbTORIS component.
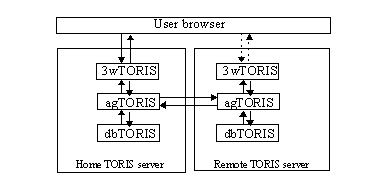 Fig. 1. TORIS architecture.
Fig. 1. TORIS architecture.
dbTORIS. Toponymy as an object of science can be represented in two projections: the synchronous (toponyms with its diversity of structural-semantic types, located on a specific area) and the diachronic one (toponyms, their structure and also their components which represent products of different time spaces). Therefore, a researcher's task in general comprises reflection of structural-semantic (and consequently chronological) peculiarities of toponymy in every part of the territory. Since each toponym represents a word (a simple, compound and suffix one) or a word combination, a researcher's major task is making lists of toponyms according to these characteristics on a certain territory.
From our standpoint, compiling of the dictionary of toponymical lexics is an extremely significant task. In this dictionary three types of toponymical components must be strictly distinguish and identified:
appelative lexics of the language presented (lexics which is out of date as well);
substratum (subsubstratum) lexics, correctly etymologized;
substratum lexics which can not be etymologized at present period of etymologization.
This will provide putting into operation all toponymical lexics of the given region.
So far a structure for describing Baltic-Fennic (Karelian, Vepsian, Finnish), Saam, and Russian languages has been developed. It pays attention both to the structural, semantic, and functional peculiarities of place-names in these languages and to extralinguistic data on the objects bearing these place-names. We partly discussed the structure of describing Russian place-names in relation to substrate problems at the Symposium "Traditional culture of Finno-Ugric and neighboring nations" in Petrozavodsk on February 9-12, 1997 [4,5].
When constant and inconstant parameters of toponym multilanguage representation had been separated we obtained a simple scheme shown in Fig.2. Constant parameters are geographical ones but inconstant are linguistic ones.
 Fig. 2. Multilanguage representation of toponym.
Fig. 2. Multilanguage representation of toponym.
The suggested structure of description will allow to obtain a wholesome notion of the place-name as a linguistic, cultural, and historic phenomenon. Multilunguage representations of the same place-name are related by toponym identificator (unique key builded according with object, republic, and equivalent of place-name in Russian). Below we show the relational database structure of TORIS, see Fig. 3.
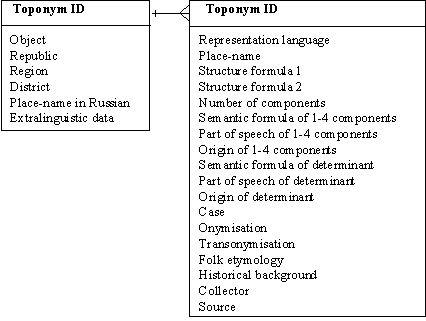 Fig. 3. Relational database structure.
Fig. 3. Relational database structure.
3wTORIS. This component consists of HTML pages and CGI scripts to statically view, edit, add toponymic data.
AgTORIS. The main goal of this component is autonomous performing tasks:
autonomous search through the TORIS servers,
correct data monitoring,
assistance to make query, input data to a user.
The architecture of agTORIS shown in Fig. 4.
Agent Server consists of two basics parts: Agent Manager (AM) and Agent Manager message queue. Agent Launcher (AL) is Java applet to provide user interface of simple agent management such as activate or deactivate an agent. After user agent manipulation AL connects to home AM to push data to the queue and then disconnects and waits for next user manipulation.
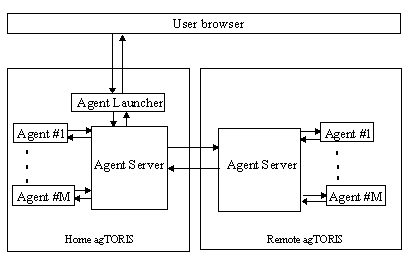 Fig. 4. agTORIS architecture.
Fig. 4. agTORIS architecture.
According to the pushed data AM activates or deactivates agents, changes agent tasks, etc. The activated agent
"lives" till AM destroys him or his "life time" is exhausted. Each agent cooperates with other agents via the home AM. Agent information exchange is organised by the AM message queue.
Here is the principal scheme of TORIS-user interaction architecture (see Fig.1):
if query result does not satisfy the user he can run agents (e.g. a search agent to further search across the TORIS servers). When agent task will be performed user can get results by browser or via mail (if user have not enough time for waiting search results).
Conclusions
In 1995 the Norwegian researcher from University of Tromso E.Soderholm suggested a project "Toponymic atlas of the Barents region". The necessity of the project was substantiated by the demand for broadening cultural, scientific, political and economic links between countries in the Barents region. The project also suggested some practical measures on its implementation.
In our opinion it is highly advisable to combine the project "Toponymic atlas of the Barents region" suggested by E.Soderholm with the project "Development of a computer data bank for place-names in the European North of Russia" in one international project covering all the countries in the Barents region. It should be mentioned that the administration of the Centre for Native Language Studies in Finland thought the idea of the joint project was interesting and expressed willingness to participate in it. If the decision is positive a coordinating centre will have to be organized which would include representatives of the countries concerned and solve scientific and organizing problems related to the project.
Related works
The investigations of design of computer-based toponymic informational system are in progress in various countries.
In 1990 R.Miikkulainen (Research Institute for the Languages of Finland, Helsinki) reported about the database of finnish toponyms at 37 International Onomastic congress. The toponyms database has to allow the integration of different kinds of toponymic data. The database is going to form a material useful for many purposes and compatible with many kinds of operating systems [6].
Basic principles of computer-based treatment of toponymic data were reported by G.Kert and V.Lebedev (KRC RAS, Petrozavodsk) at Scientific Council of KRC RAS [1]. In the report principal structure types of karelian, saam, and russian toponymy have been shown.
In 1994 M.Gorbanevsky (Institute of Russian Language, Moscow) designed the computer-based toponymic dictionary of Moscow [2,3]. The structure of a dictionary article consists of five parts: address, chronology, etymology, culture and history, spelling. The dictionary is most complete repository of the Moscow toponymic data.
Acknowledgements
We would like to thank Russian Ministry for Science and Technical Policy for including this project in the schedule of scientific research and financial support.
References
G.M.Kert, V.A.Lebedev. Vozmoghnosti primeneniya IBM pri issledovanii toponimii evropeiskoy chasti SSSR //
Preprint doklada Karelsky nauchny centr, 1988.
M.B.Gorbanevsky. Russkaya gorodskaya toponimiya: problemy istoriko-kulturnogo izucheniya i ssovremennogo
leksikographicheskogo opisaniya // Avtoreferat, Institut russkogo yazzyks im. A.S.Pushkina, 1994.
M.B.Gorbanevsky, V.V.Presnov. Toponimika i komputernaya leksikografiya // Posev, 1993.
G.M.Kert. Problema vyayleniya substrata v proiecte "Komputerny bank toponimii Evropeiskogo Severa Rossii"
//Tezisy dokladov k mezdunarodnomu Symposiumu "Traditsionnaya kultura finno-ugrov i sosednikh narodov", p. 53-57, Petrozavodsk, 1997.
A.L..Veretin. Voprosy razrabotki komputernogo banka toponimii Evropeiskogo Severa Rossii // Tezisy
dokladov k mezdunarodnomu Symposiumu "Traditsionnaya kultura finno-ugrov i sosednikh narodov", p. 69-71, Petrozavodsk, 1997.
R.Miikkulainen. Die finnische Ortsnamenbank // Proceedings of the XVII International Congress of
onomastic
Sciences, v.2, pp. 171-178, Helsinki, 1990.
|